NameNode is the control center of HDFS. It manages the filesystem metadata for the entire cluster, so in the early Hadoop 1.x design, having only one NameNode created a serious reliability problem: if that node failed, HDFS effectively stopped working.
Hadoop 2.x introduced a high-availability architecture to remove that single point of failure. By using an Active/Standby NameNode pair, along with metadata synchronization and automatic failover, HDFS can keep running even when one NameNode goes down.
Why NameNode HA became necessary
In Hadoop 1.x, the NameNode was responsible for several critical tasks:
- maintaining the directory tree and other metadata
- receiving client requests
- handling heartbeats from DataNodes
- processing metadata updates for read/write operations
The problem was simple but severe: there was only one NameNode.
If that node crashed:
- HDFS could no longer serve reads or writes
- metadata became inaccessible
- DataNodes lost the central node they depended on for coordination
- the whole system became unavailable
Because of this, eliminating the NameNode as a single point of failure became a fundamental requirement in Hadoop 2.x.
What HA in HDFS is designed to solve

HDFS high availability is not just about keeping a backup machine around. It addresses several system-level issues at once.
Removing the NameNode single point of failure
The most direct goal is to use an Active and a Standby NameNode so that when the primary one fails, another can take over quickly and keep HDFS available.
Keeping metadata consistent across NameNodes
Once multiple NameNodes exist, the core challenge becomes consistency. Both nodes must agree on the same metadata state, which is why mechanisms such as QJM or shared storage were introduced.
Laying the foundation for Federation
Hadoop 2.x also supports multiple NameNodes managing different namespaces. This enables metadata to scale horizontally and is an important architectural step toward Federation.
The basic HA model: Active and Standby NameNode
When HDFS HA is enabled, two NameNodes run together:
<table> <thead> <tr> <th>Name</th> <th>State</th> <th>Responsibility</th> </tr> </thead> <tbody> <tr> <td>Active NN</td> <td>Primary</td> <td>Handles all client read/write requests and communicates with clients and DataNodes</td> </tr> <tr> <td>Standby NN</td> <td>Secondary</td> <td>Does not serve client requests; focuses on metadata synchronization and checkpointing</td> </tr> </tbody> </table>The Standby node is kept ready to take over at any time.
The key requirement is that both nodes must stay synchronized in metadata state as closely as possible.
What NameNode metadata consists of
On disk, HDFS metadata is mainly represented by two kinds of files.
Fsimage
- a full snapshot of the filesystem state
- includes the directory tree, file attributes, block mappings, and related metadata
- not updated frequently, because writing a full snapshot is expensive
EditLog
- an incremental operation log, similar in idea to a MySQL binlog
- written very frequently
- every metadata change, such as create, delete, or rename, is recorded here
Both are necessary because they serve different purposes. Fsimage gives a static full snapshot, while EditLog records everything that happened after that snapshot.
When a NameNode starts, it reconstructs the latest metadata using:
Fsimage + EditLog = 最新完整元数据
Why checkpointing is necessary
As HDFS keeps running, EditLog grows continuously. If it is left unchecked, startup and recovery become slower because the NameNode has to replay a larger and larger log.
To avoid that, the system periodically merges EditLog into a new Fsimage. In the HA architecture, this checkpointing work is handled by the Standby NameNode. This effectively absorbs the responsibility that used to belong to the SecondaryNameNode.
Checkpointing is triggered by configuration thresholds such as:
<table> <thead> <tr> <th>Configuration</th> <th>Meaning</th> </tr> </thead> <tbody> <tr> <td>dfs.namenode.checkpoint.period</td>
<td>how many seconds between checkpoint attempts</td>
</tr>
<tr>
<td>dfs.namenode.checkpoint.txns</td>
<td>how many edit log transactions trigger a checkpoint</td>
</tr>
</tbody>
</table>
How the checkpoint process works
The Standby NameNode performs checkpointing through a series of coordinated steps.
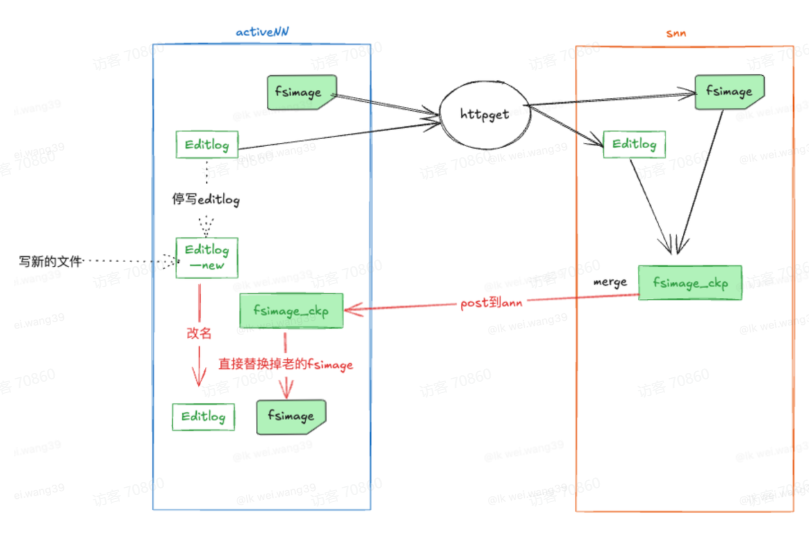
Step 1: Standby decides whether a checkpoint is needed
It checks two conditions:
- whether the configured time interval has been reached
- whether the number of EditLog transactions exceeds the threshold
If neither condition is met, it simply waits.
Step 2: Active rolls the EditLog
Once the Standby requests a checkpoint, the Active NameNode rotates the current edit log.
It does this by:
- stopping writes to the current EditLog
- creating a new file:
edits_inprogress → edits_inprogress_new
Subsequent metadata changes are written to the new file.
This makes the old EditLog stable and complete, so it can be safely downloaded and merged.
Step 3: Standby downloads the metadata files
The Standby fetches the necessary files over HTTP:
- the latest Fsimage
- the complete EditLog file
After downloading them, it prepares for the merge.
Step 4: Standby merges the metadata
The merge process is straightforward in principle:
- load the current Fsimage snapshot
- replay the EditLog entries in order
- reconstruct the newest metadata state
- write out a new
fsimage.ckptfile
Step 5: The merged result is returned to Active
The Standby then makes the generated fsimage.ckpt available to the Active NameNode.
The Active performs two operations:
- replace the old fsimage with the new one
- rename
editlog_newinto the formal EditLog
This allows metadata to switch over cleanly without interrupting normal operation.
The heart of HA: keeping metadata consistent
High availability only works if both NameNodes see the same metadata state. Otherwise, a failover could leave the namespace inconsistent or corrupted.
Hadoop 2.x mainly provides two approaches for this.
QJM (Quorum Journal Manager)
This is the most common and recommended solution.
QJM uses a JournalNode cluster, usually 3 or 5 nodes, to store EditLog data.
The flow is:
- Active NameNode writes EditLog entries to multiple JournalNodes
- Standby NameNode pulls those logs from the JournalNodes
Consistency is guaranteed by a quorum mechanism:
少数派容错(quorum)机制
An EditLog write is considered successful as long as more than half of the JournalNodes acknowledge it.
Its advantages are clear:
- strong consistency
- recoverability after failures
- well suited for production environments
NFS-based shared storage
Another option is to place EditLog on shared storage mounted through NFS.
This approach is now largely outdated because it has obvious limitations:
- the NFS server can become a new single point of failure
- performance is weaker
- it does not fit large-scale clusters well
How failover happens
Automatic failover in HDFS HA is handled by ZKFC, the ZooKeeper Failover Controller.
ZKFC is responsible for:
- health checking the NameNode
- heartbeat coordination
- electing which node is Active and which is Standby
- triggering automatic failover when needed
A switch can happen when:
- the Active NameNode crashes
- the Active loses connection to ZooKeeper
- administrators initiate a manual switchover
With this mechanism in place, client operations can continue without being disrupted by a single NameNode failure.
A compact way to explain NameNode HA
A concise way to describe it is this: Hadoop 2.x introduced NameNode HA to solve the single-point-of-failure problem that existed in Hadoop 1.x. HDFS runs with an Active/Standby NameNode pair, and ZKFC handles health checks and automatic failover. Metadata is composed of Fsimage and EditLog, while the Standby NameNode periodically performs checkpointing by rolling the EditLog, downloading the necessary metadata, merging it into a new fsimage, and handing the result back to the Active node. In production, QJM with a JournalNode cluster is the standard way to keep EditLog synchronized and maintain strong consistency.