Overview
A skip list speeds up operations on an ordered linked list by promoting some nodes into multiple layers. Each layer is still an ordered linked list, but searches begin at the highest level and move forward there first. When the next node is greater than the target value, or the forward pointer is NULL, the search drops down one level and continues.
That layered structure reduces the number of comparisons. In the example below, searching for 51 in a skip list follows 1 -> 21 -> 41 -> 51, so it takes 4 steps. A plain linked list would need 1 -> 11 -> 21 -> 31 -> 41 -> 51, which takes 6 steps. The gap becomes much more noticeable as the dataset grows.
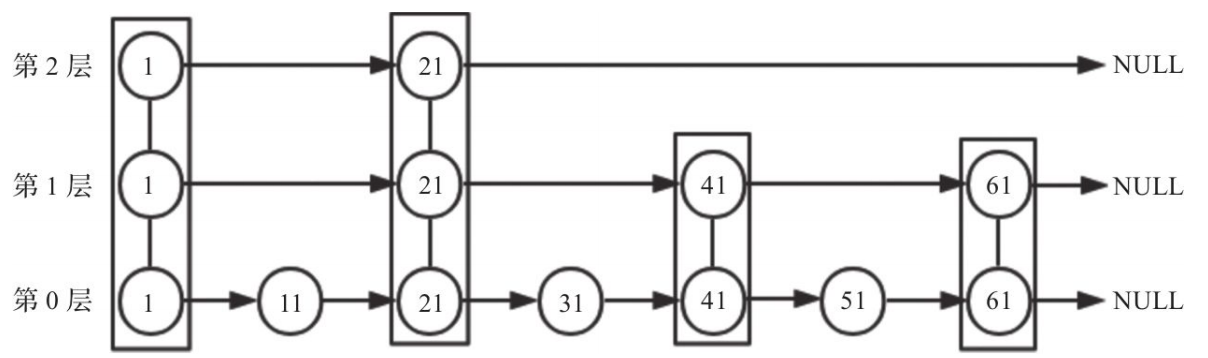
The overall construction looks like this:
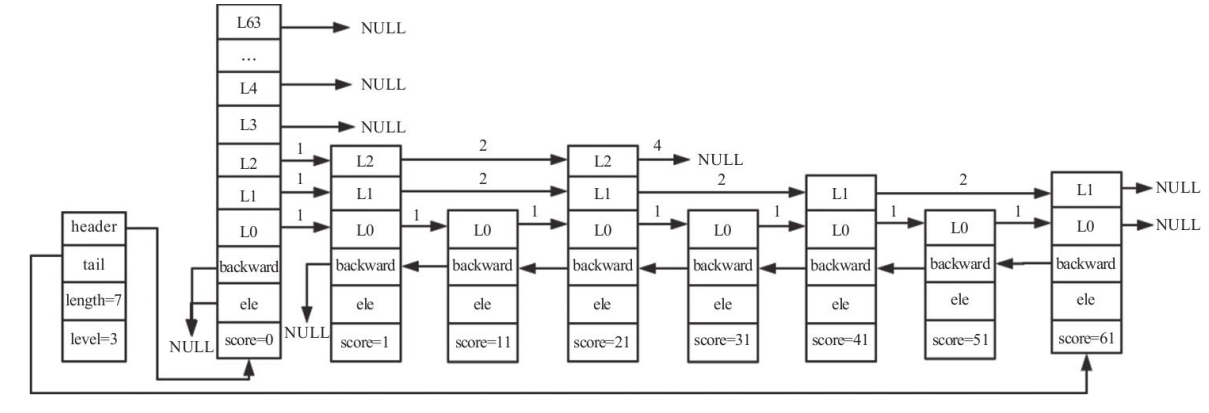
A Redis-style skip list has these characteristics:
- It is made of multiple levels.
- It has a
headernode whose internal structure reserves 64 levels in the older design. Each level stores a pointer to the next node at that level and aspan, which records how many nodes are skipped over. - Excluding the header, the tallest node determines the skip list height (
level). In the diagram above, the height is 3. - Every level is an ordered linked list with increasing values.
- If an element appears in an upper level, it must also appear in every lower level beneath it.
- The last node in each level points to
NULL. - The skip list keeps a
tailpointer to the last node. - The bottom level contains all nodes. The number of nodes in that bottom list is the skip list
length. - Each node also keeps a backward pointer. The header and the first node have
NULL; every other node points to its predecessor on the bottom level.
Because each node maintains multiple forward pointers, search, insert, and delete operations can skip over parts of the structure instead of walking one node at a time. In essence, a skip list trades extra memory for faster lookup.
Data structures used by the skip list
A skip list is built from nodes, and each node contains one or more levels. Every level has a pointer to the next node in that layer.
Node structure
Redis uses the following zskiplistNode structure:
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
What each field means:
ele: stores string data.score: stores the numeric value used for ordering.backward: points only to the previous node on the bottom level. The header node and the first node useNULL. This is used for reverse traversal.level: a flexible array member. Its length differs from node to node. When a node is created, a random height between 1 and the maximum level is chosen; higher levels are increasingly rare.forward: within one level, points to the next node. The last node points toNULL.span: the number of elements between the current node and the node referenced byforward. Larger spans mean more nodes are skipped.
In Redis sorted sets, skip lists are one of the underlying implementations. For that reason, ele stores the member value and score stores the member score. Nodes are ordered by ascending score; if two members have the same score, ordering falls back to lexicographical comparison of the member string.
Skip list structure
The nodes alone are not enough; Redis also uses a container structure to manage the whole list:
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
Its fields are:
header: points to the special header node. The header stores no member and no score, soeleisNULLandscoreis0. It is not counted in the skip list length. During initialization, all of itsforwardpointers are set toNULLand allspanvalues are0.tail: points to the last node.length: total number of nodes excluding the header.level: the current height of the skip list.
With this structure, the program can access the header, tail, length, and height in O(1) time.
Basic skip list operations
Creating a skip list
How node height is chosen
A node must have at least one level, and its height cannot exceed ZSKIPLIST_MAXLEVEL. In Redis 5, that maximum was 64. In Redis 6 and Redis 7, it was reduced to 32.
The reason is practical. The original official design could theoretically support a skip list large enough for 2^64 elements. With ZSKIPLIST_P = 0.25, the probabilistic model implies capacity on the order of 4^64, which wastes a large amount of space. So the maximum level was lowered to 32 to reduce resource waste.
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
Redis generates a random node height with zslRandomLevel, returning a value from 1 to 32. Higher levels appear with lower probability:
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
int zslRandomLevel(void) {
/* 计算阈值 */
static const int threshold = ZSKIPLIST_P*RAND_MAX;
int level = 1;
/* 当随机数小于阈值时,level 继续增加 */
while (random() < threshold)
level += 1;
/* 返回 level,同时做不要让 level 大于最大层数的操作 */
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
This function starts from level 1. While the generated random number stays below 0.25 * RAND_MAX, the level increases. The final value is capped at ZSKIPLIST_MAXLEVEL.
That leads to the following probability distribution:
- The probability of level 1 is
1 - p. - The probability of level 2 is
p(1 - p). - The probability of level 3 is
p^2 (1 - p). - In general, the probability of level
kisp^k (1 - p).
Initializing a node
Each skip list node belongs to an ordered set of elements. When it is created, its height, score, and ele are already known, so the system allocates exactly enough memory for the flexible level[] array.
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
The key point is this allocation:
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel))
The header node is special. Its backward pointer is NULL, and since it starts as the first node in the structure, each forward pointer is also initialized to NULL, with each span set to 0:
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
Creating the skip list object
The creation process is straightforward:
- Allocate memory for the
zskipliststructure. - Create and initialize the header node.
- Initialize the remaining fields:
length = 0,backward = NULL,tail = NULL.
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
/* 初始化每层跳表 */
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
Inserting a node
Insertion is the most common skip list update. The process can be broken into four parts:
- Find the insertion position.
- Raise the skip list height if needed.
- Create the node and link it into each relevant level.
- Fix
backwardpointers and untouched spans.
Finding where to insert
Search starts from the highest current level and moves down. Redis uses this logic:
/* 从最高层向下查找插入位置 */
for (i = zsl->level-1; i >= 0; i--) {
/* rank 存储到达插入位置而跨越的节点数 */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;存储到达插入位置而跨越的节点数
x = x->level[i].forward;
}
update[i] = x;
}
Two helper arrays are essential here, both sized to the maximum number of levels:
update[]: stores, for each level, the node that will become the predecessor of the new node.rank[]: stores how many steps have been crossed from the header toupdate[i]. This is later used to compute correctspanvalues.
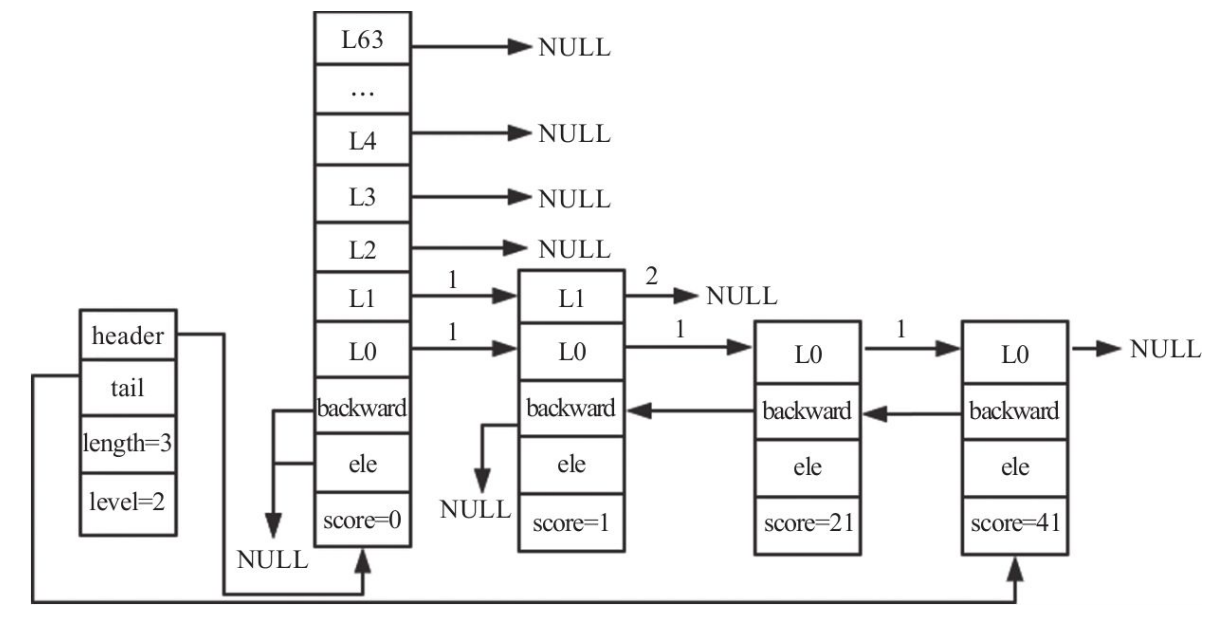
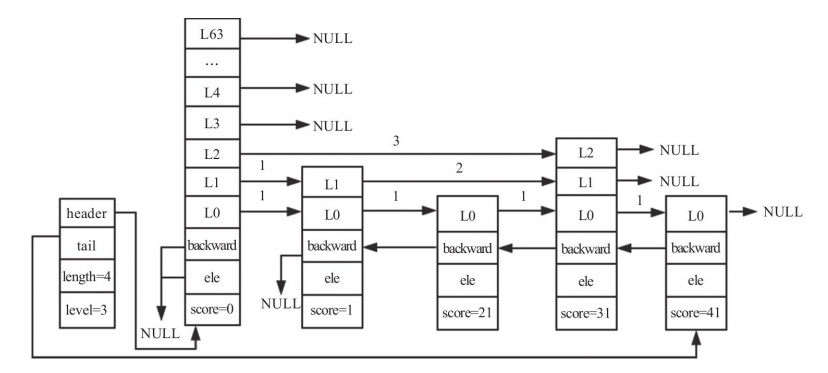
In the example shown, the skip list has length 3 and height 2. A node with score 35 and height 3 is about to be inserted. After the search, rank and update look like this:
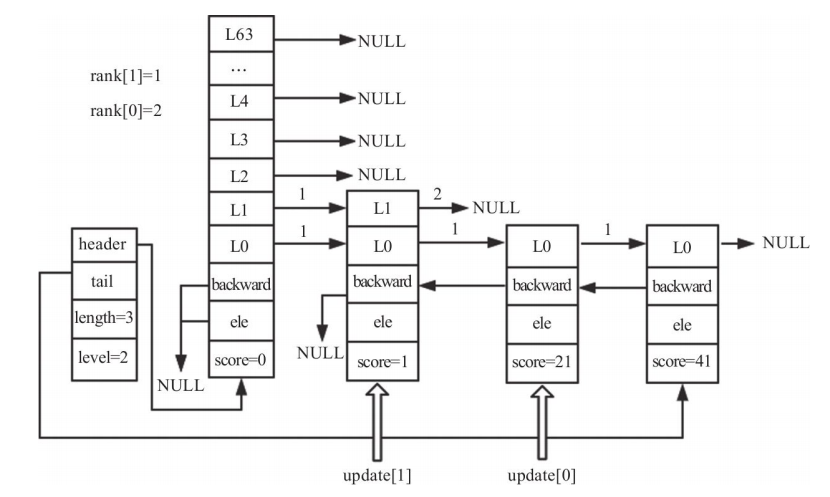
Adjusting the skip list height
Because a new node’s height is random, it may be taller than the current skip list. If the new node has height 3 while the list height is only 2, the skip list must grow first.
/* 获取随机最高层数 */
level = zslRandomLevel();
/* 随机获取的 level 比跳表原来的 level 大,则在比原来 level 高的层级上初始化 rank 和 update */
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
/* 将跳表的 level(最高层数) 替换为随机获取到的 level */
zsl->level = level;
}
For the newly added upper levels, update[i] is set to the header, rank[i] starts at 0, and the header span for those levels is initialized to the full current length.
The structure after increasing the height is illustrated here:
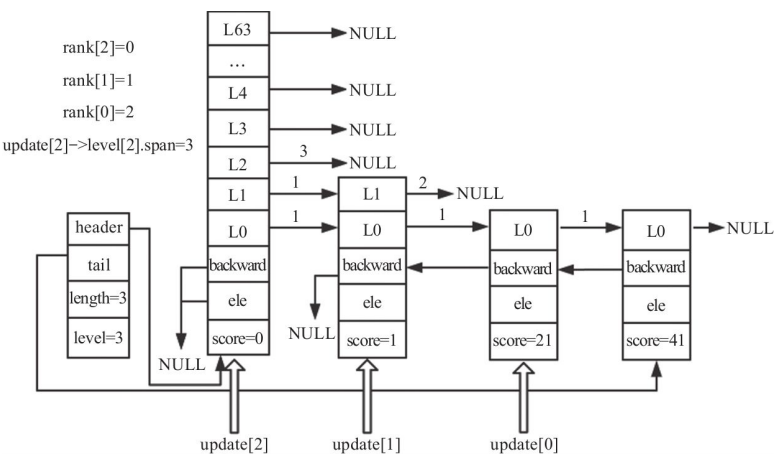
Creating and linking the new node
Once update[] and rank[] are ready, the node can be created:
/* 创建一个具有指定层数的跳表节点, SDS字符串 'ele' 在调用后被节点引用 */
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn = zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
Then the insertion itself updates pointers and spans level by level:
/* 插入新节点 */
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* 更新 update[i] 所涵盖的跨度,因为有新节点(x)被插入了 */
/* 首先更新新节点的跨度 */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
/* 更新 update 的跨度 */
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
This code does two things at each involved level:
- It inserts the new node between
update[i]and the former next node. - It recalculates spans so that index-related operations remain correct.
After updating level 0:
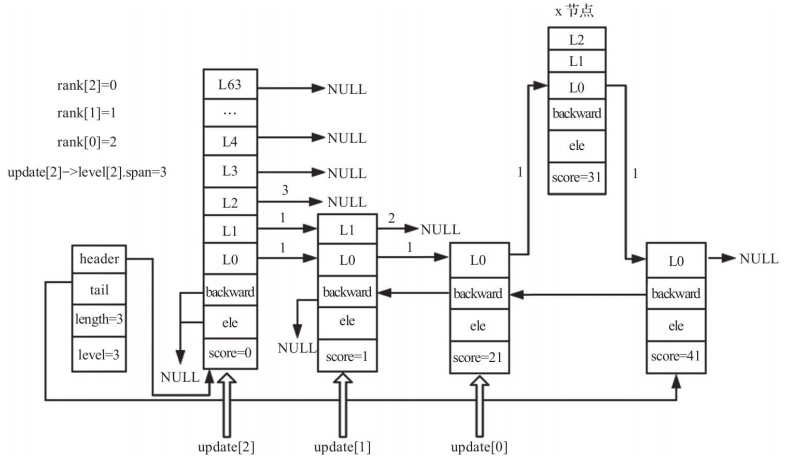
After updating level 1:
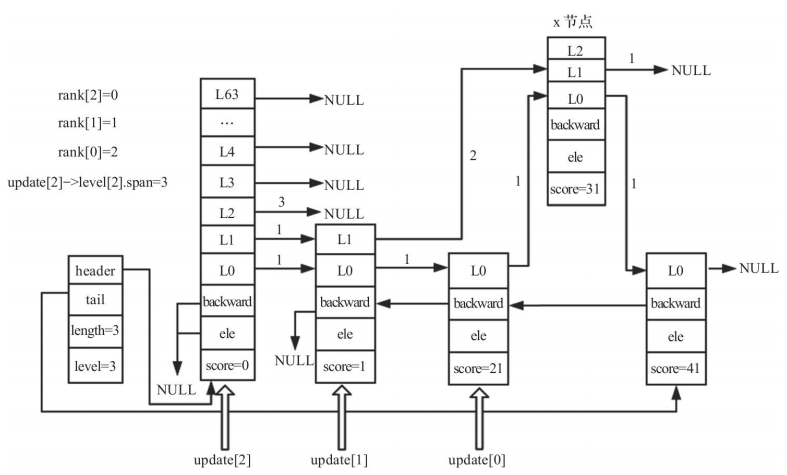
After updating level 2:
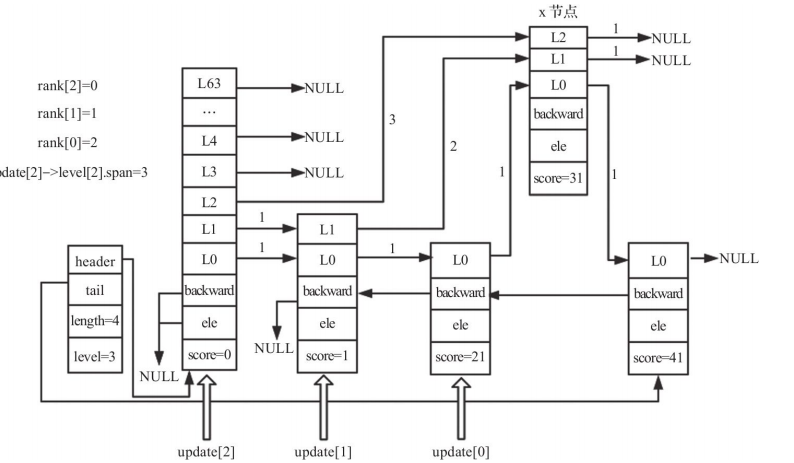
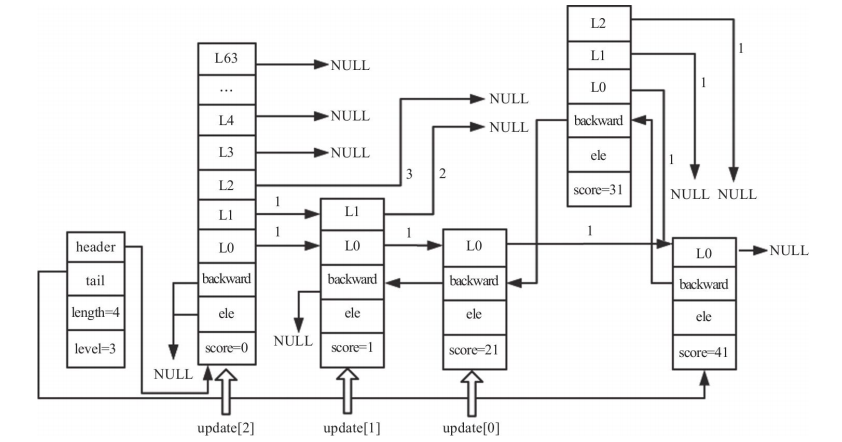
Updating untouched spans and backward pointers
If the new node does not reach all the way to the current top of the skip list, the higher untouched levels still need their spans adjusted:
/* 对未触及到的层数(插入节点的最高层与整个跳表中最高层之间)更新跨度 */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
Then the backward links are fixed:
x->backward = (update[0] == zsl->header) ? NULL : update[0];
/* 设置新节点的下一个节点的后向指针,若下一个节点不存在,则将尾指针指向新节点 */
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
The final result after insertion looks like this:
Deleting a node
Deletion follows a similar pattern:
- Find the node to remove.
- Update
spanandforwardpointers. - Fix the backward pointer and possibly shrink the skip list height.
Locating the target node
The search logic is the same as when finding an insertion position. The traversal identifies the predecessors that need to be updated once the target is removed.
Updating spans and forward pointers
Span updates are handled like this:
/* 更新 update[i] 的前向指针以及跨度 */
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
If a level directly points to the node being deleted, the pointer is bypassed and the span is merged accordingly. If not, the path still loses one node beneath it, so the span is decremented.
The backward pointer update is:
/* 更新 x(被删除节点) 的下一个节点的后向指针,如果下一个节点不存在,则将尾指针指向 x 的上一个节点 */
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
If the removed node was the only node on the highest level, the skip list height must be lowered until the top level is non-empty again:
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
After these adjustments, the structure becomes:
Freeing the entire skip list
Destroying a skip list starts from level 0 of the header and walks forward node by node, freeing each one. After all regular nodes are released, the skip list object itself is freed.
/* 释放整个跳表 */
void zslFree(zskiplist *zsl) {
zskiplistNode *node = zsl->header->level[0].forward, *next;
/* 释放头指针 */
zfree(zsl->header);
/* 遍历并释放剩下的所有节点 */
while(node) {
next = node->level[0].forward;
zslFreeNode(node);
node = next;
}
/* 释放跳表结构 */
zfree(zsl);
}
Freeing a single node also releases its referenced SDS string, unless node->ele has been set to NULL in advance:
void zslFreeNode(zskiplistNode *node) {
sdsfree(node->ele);
zfree(node);
}
Where skip lists are used
In Redis, skip lists are one of the underlying implementations for sorted sets (zset). Their internal combination with a dictionary looks like this:
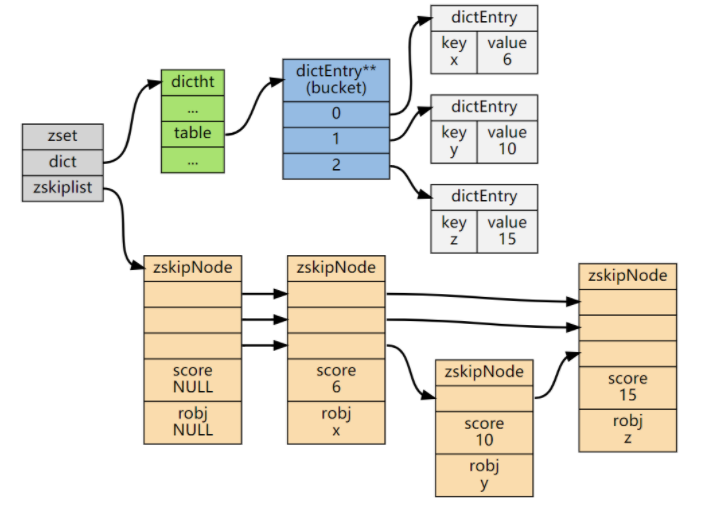
Typical use cases include:
Leaderboards
Sorted sets are a natural fit for ranking scenarios. A video platform, for example, may maintain multiple rankings for uploaded content based on time, view count, likes, or similar metrics.
Weighted queues
Another common use is queue-like structures where ordering depends on priority or weight rather than arrival time alone.
Related configuration parameters
Redis exposes a few parameters related to zset storage: